The Therac-25 killed patients while the monitor said “no error.” Your pipeline is one race condition away from the same failure.

Between June 1985 and January 1987, six patients received radiation doses between 40 and 200 times the prescribed therapeutic level from a machine that had been certified, reviewed, and considered an improvement over every model before it. At least three died from their injuries. The Atomic Energy of Canada Limited’s Therac-25 reported no error each time. Operators, following training, pressed continue. The Therac-25’s predecessor had hardware interlocks: physical mechanisms that made a lethal dose mechanically impossible regardless of software state. Engineers removed them when designing the new model. The software was handling it. The hardware was redundant.
In your cloud environment, the equivalent of those removed interlocks is the network-level control replaced by a security group rule, the hardware token replaced by a software MFA policy, the subnet ACL removed because the application firewall was “already doing that.” The Therac-25 is not a story about a bug in an obscure medical device. It is a story about what happens when trust in software eliminates independent verification of its output.
The race condition you cannot see from the console
| Date | Facility | Reported Machine Status | Actual Dose Delivered | Operator Action | Patient Outcome |
|---|---|---|---|---|---|
| 3 Jun 1985 | Kennestone Regional Oncology Center | “Malfunction 54” / apparent underdose | ~15,000–20,000 rad (~100× prescribed) | Operator pressed P (“Proceed”) to continue treatment after machine pause | Severe radiation burns; mastectomy required; long-term injury (VastBlue Innovations) |
| 26 Jul 1985 | Ontario Cancer Foundation | “H-tilt”, dosimeter indicated little/no dose | ~13,000–17,000 rad (~65–85× prescribed) | Operator repeatedly pressed Proceed after pauses | Massive tissue destruction; patient later died with overdose-related complications (Wikipedia) |
| Dec 1985 | Yakima Valley Memorial Hospital | “Malfunction 54” | Massive overdose (exact dose uncertain) | Operator resumed treatment believing underdose occurred | Severe striped radiation burns and tissue injury (Wikipedia) |
| 21 Mar 1986 | East Texas Cancer Center | “Malfunction 54” / machine indicated only 6 of 202 units delivered | Estimated ~20,000–25,000 rad (~125× prescribed) | Operator pressed P to continue after first fault | Patient suffered catastrophic radiation injury and later died (VastBlue Innovations) |
| 11 Apr 1986 | East Texas Cancer Center | “Malfunction 54” | Massive overdose to face and temporal lobe | Operator pressed Proceed after “Beam ready” appeared | Severe neurological damage; patient died May 1986 (Wikipedia) |
| 17 Jan 1987 | Yakima Valley Memorial Hospital | “Malfunction 54” followed by “Flatness” | ~8,000–10,000 rad instead of prescribed 86 rad (~100× overdose) | Operator pressed Proceed after believing little dose had been delivered | Severe chest burns and radiation injury; patient died Apr 1987 (Wikipedia) |
The Therac-25 software had a race condition. If an operator entered patient setup parameters and then moved to a cursor position to make a correction quickly enough, a timing window of approximately 8 seconds would open in which the machine engaged the 25 MeV electron beam at full power without the metal scanning plates in position. Without those plates, the beam was not diffused across the treatment field. It struck tissue directly, at concentrated intensity, at doses orders of magnitude above therapeutic levels.
The window required speed. Slow typists could not close it fast enough to trigger the bug. Proficiency with the system was the attack surface. The operators who injured their patients were the most experienced users at the busiest treatment centres. They had learned to enter parameters efficiently. That efficiency killed people.
When the race condition fired, the machine displayed one of several low-priority error codes. “MALFUNCTION 54” appeared regularly. The operator manual listed it as a minor notification. Operators had seen it dozens of times. Nothing had gone wrong when they pressed the ‘P’ key to proceed. The training was clear: minor fault, proceed. So they pressed P. The patient on the table had received a lethal dose. The monitor said: no error. Continue.
Race conditions in cloud infrastructure are a standard failure category, not an edge case. A Lambda function that assumes state consistency across concurrent invocations when it has none. A Terraform plan reading current state from a backend that has drifted from actual resource configuration. A CI/CD pipeline that validates a container image digest at job start and pulls the image again five steps later, after a push has replaced it. None of these surface as errors in nominal conditions. All of them can deliver the equivalent of a 200x radiation dose to a production environment while the dashboard reports green.
Hardware locks exist for a reason: the price of software elegance
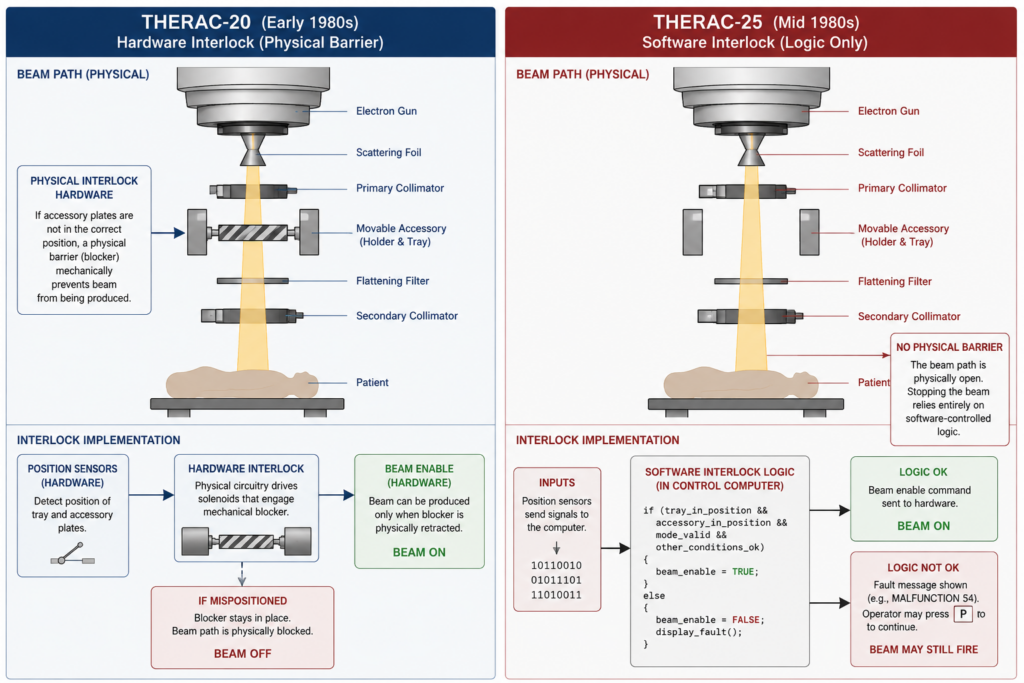
The Therac-20 had hardware interlocks built into the machine’s physical design. If the scanning plates were not confirmed in position, a mechanical interlock prevented the beam from firing. Software state was irrelevant. The hardware blocked it. The consequence of a software failure was bounded by physics.
AECL’s engineers did not remove those interlocks out of negligence. They had examined the Therac-20’s operational record. The software controls had worked correctly throughout. The reasoning was logical: the software handles this, we have had no failures attributable to the hardware interlocks, maintaining redundant hardware adds cost and complexity. The decision to remove them was a reasonable engineering call based on available evidence.
This reasoning is structurally identical to every conversation about removing compensating controls in cloud architecture. Removing subnet-level ACLs because security groups are configured. Disabling certificate pinning because mutual TLS is already in place. Dropping MFA hardware token requirements because the identity provider enforces software MFA. Each decision is defensible in isolation. The aggregate effect is the elimination of independent verification: a second check that operates on a different mechanism and cannot be bypassed by the same failure mode that defeats the primary control.
In regulated environments, defence in depth is supposed to prevent this. In practice, the drive toward infrastructure simplification, cost reduction, and reduced operational overhead produces the same trade-off AECL made. The hardware lock is removed. The software control remains. When the software has a race condition, there is nothing left to catch it.
The Hardware Lock Principle applied to cloud security has one core requirement: every critical control must have an independent verification layer that operates on a different mechanism and cannot be defeated by the same failure mode. Not a second software check. A structurally different check.
The action: audit every security control in your environment and identify whether it has an independent verification layer operating on a different mechanism. If the answer for a Tier 1 control is “none,” you have found your Therac-25.
The proficiency paradox: your most experienced engineers are your highest-risk operators
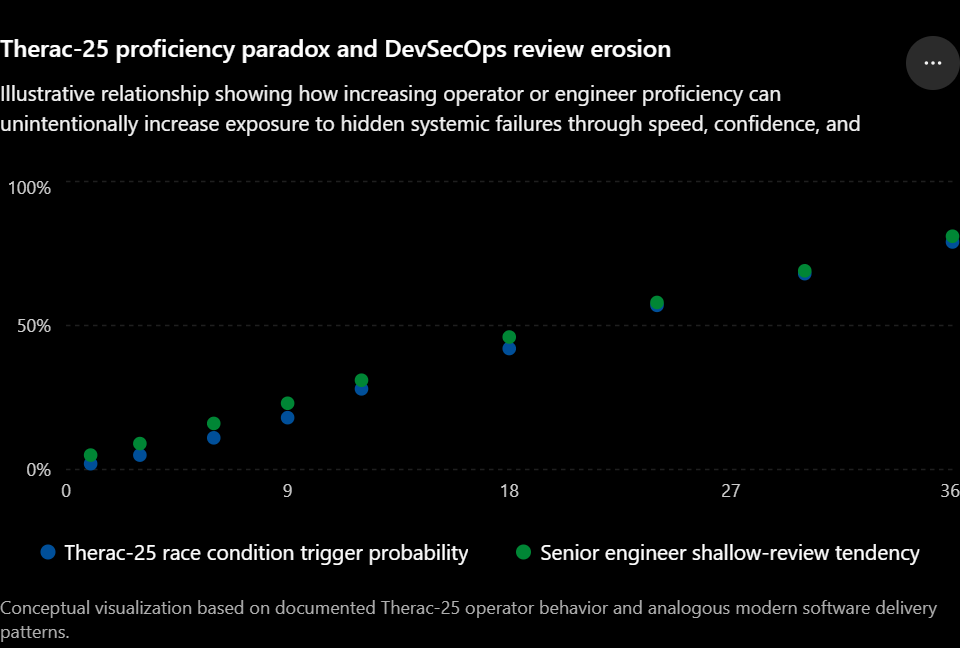
Nancy Leveson and Clark Turner’s 1993 IEEE Computer analysis of the Therac-25 case is still the definitive technical post-mortem. One of their sharpest findings: the system’s failure mode was specifically activated by experienced users. Novices, uncertain and slow, could not trigger the race condition. Veterans, efficient and confident, could and did. The investigation identified this as a fundamental design failure: a safety-critical system where competence increased risk.
The system punished expertise. That finding has a direct parallel in every DevSecOps team operating mature automation.
Senior engineers approve Terraform plans at speed because they have approved hundreds of plans. The cognitive pattern is: this looks like the last 400. It probably is. The security group modification on line 847 of a 900-line plan output is in the diff. They do not see it. They were not looking at line 847. They were looking at the summary. The pipeline reports no error. The change deploys. SSH ingress is now permitted from 0.0.0.0/0 in the production VPC.
Junior engineers run additional checks. They are uncertain of what they are looking at. That uncertainty makes them safer. Seniority, expressed as pattern-matching confidence, is a risk amplifier when automation handles the nominal cases and humans are only watching for anomalies they expect to see.
The proficiency paradox also applies to AI-assisted code review. A senior engineer reviewing GitHub Copilot or Amazon CodeWhisperer output brings strong pattern-matching capability to the review. They are also more likely to approve code that looks structurally correct even when the logic contains a subtle vulnerability, because their review is calibrated to the patterns they have seen before. Novel vulnerability classes are not in that pattern library.
The action: establish mandatory automated flagging for specific change categories (security group inbound rule modification, IAM policy change, S3 bucket policy update, KMS key rotation, root account activity) regardless of pipeline success status. Route flagged changes to a second reviewer who was not involved in writing or approving the original plan. Senior seniority does not exempt a change from this routing.
“MALFUNCTION 54”: the alert your team has been trained to dismiss
Every operator who pressed the ‘P’ key on a Therac-25 had a reasonable basis for doing so. They had pressed it before. Nothing had gone wrong. The training said: minor fault, proceed. The documentation confirmed: low-priority notification. The institutional knowledge, built through repetition, was: this code is noise. Dismiss it. Continue.
AECL’s initial response to the first injury reports was to attribute them to operator error and send a letter to customers confirming the machine was safe. The FDA at the time had no established mechanism to track software-related adverse events in medical devices as a category. Individual complaints reached AECL separately. Each was an outlier. The pattern was invisible to everyone looking at individual cases rather than the aggregate.
Every DevSecOps team has a MALFUNCTION 54. It is not the same alert in every organisation, but the pattern is consistent. A Snyk finding at CVSS 6.8, marked “accepted risk” fourteen months ago because remediation requires a major version bump and nobody has a window. A CloudTrail anomaly that fires every Tuesday during batch processing, suppressed because it has never corresponded to an incident. A container image with a known CVE in a transitive dependency, below the threshold that blocks the build. Low priority. Press P. Proceed.
The failure mode is identical to 1986. Individual alerts, reviewed in isolation, look manageable. Reviewed as a cluster over time, they may be the pattern that indicates a systemic control failure that has been generating evidence for months. The radiation dose was being delivered before anyone noticed the pattern. The operators had pressed continue 47 times.
The action: run a suppression audit. Pull every dismissed, accepted, or suppressed alert from the last 90 days across your security tooling. Group by control domain and finding type. Any cluster showing more than 10 dismissals of the same finding category should be treated as a candidate for systematic control failure review, not individual alert triage.
Software-only controls are a design choice with known failure modes
The Therac-25 engineers had evidence for their confidence. The Therac-20 software had performed correctly throughout its operational life. Testing had been conducted. The team had not observed failures in the software controls. Their trust was based on a track record, not wishful thinking.
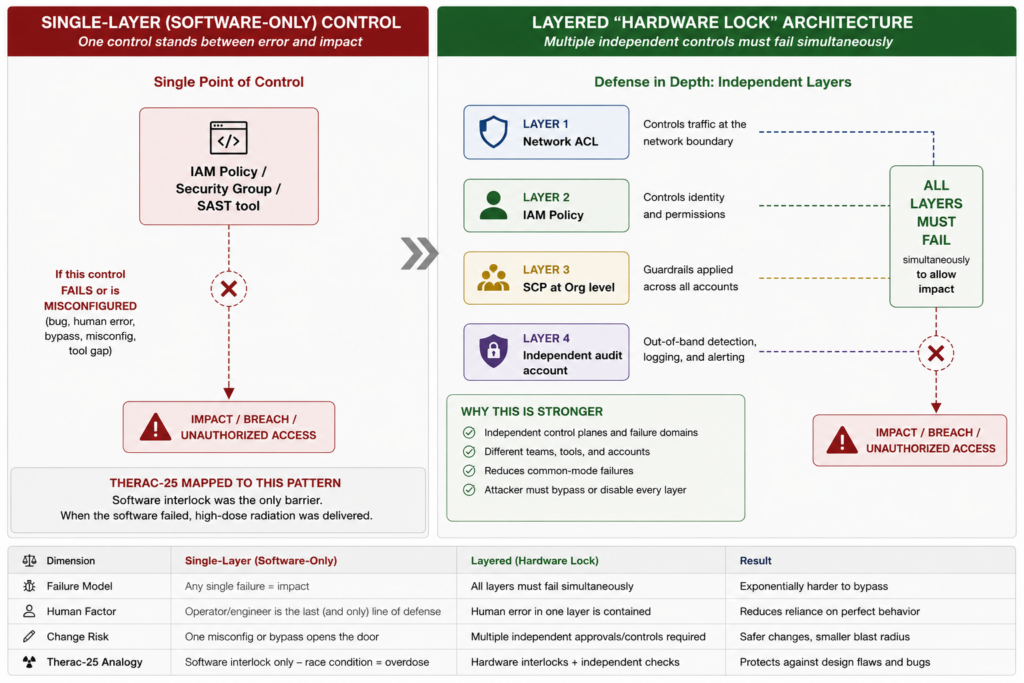
The problem was not that they trusted software. The problem was that they trusted it absolutely, and removed the mechanism that operated independently of the software to confirm its output was correct. When the software had a race condition, there was no check that could see it. The only thing verifying correctness was the thing with the error.
IaC drift is the cloud equivalent of this failure mode. The Terraform state file reflects the intended configuration. The actual EC2 security group was modified manually by an engineer resolving a P1 incident at 2am last Thursday. The diff between state and reality is invisible to any control that reads from the state file. A compliance tool reporting on Terraform state is reporting on intent, not on what is actually deployed. It will report compliant while the misconfiguration is in production. No error. Continue.
The controls that avoid this pattern operate on a different mechanism than the primary control they verify. AWS Config rules with independent remediation evaluate actual resource configuration, not IaC state. SCPs applied at the AWS Organisation level override IAM policies within any account in the Organisation and cannot be bypassed by any IAM change within a member account. Network ACLs applied at the VPC subnet level operate independently of security group configuration. Immutable S3 Object Lock with cross-account write-only access produces an audit trail that cannot be modified by any principal in the account generating the events. None of these are redundant controls. They are structurally different controls.
The action: for each critical control in your environment, apply the Hardware Lock test: does this control operate on a different mechanism than the failure mode it is supposed to catch? If the answer is no, it is not an independent control. It is a second instance of the first control, and it will fail by the same mechanism.
Regulatory invisibility: when no one is aggregating the failures

The six Therac-25 incidents occurred at multiple facilities across North America. No central reporting mechanism existed to aggregate software-related medical device adverse events in 1985. Each facility that experienced an incident initially believed it was alone. AECL received individual complaints and could frame each as an isolated operator error. It took external academic investigation by Leveson, Turner, and others to reconstruct the full pattern across facilities, timelines, and software versions.
The investigation that eventually produced accountability required looking across cases rather than within them. The individual case was ambiguous. The pattern was not.
This is the architecture of most cloud security logging estates. CloudTrail events in Account A do not automatically correlate with VPC flow logs in Account B. An attacker who compromises a developer account, escalates privileges through a shared services account, and pivots to a production environment may generate alerts in four separate systems, none of which have visibility into the other three. Each alert looks like a minor anomaly. The full attack chain, viewed end to end, is a complete breach. Four separate low-priority tickets. One systemic compromise.
The failure mode is not a lack of logging. It is a lack of correlation. You may have every log the Therac-25 ever generated. If those logs are not joined across systems and reviewed for patterns, you have the same visibility the FDA had in 1986: individual incidents, no aggregate picture, and a plausible local explanation for each one.
Worse: if audit logs are stored in the same account as the controls they monitor, a compromised account with sufficient IAM privileges can modify the log destination policy and suppress the evidence of its own compromise. The Therac-25 pattern precisely: the system checking for errors is the system with the error.
The action: test your logging architecture rather than assume it. Generate a deliberate low-signal event chain across at least three accounts and confirm it produces a single correlated, actionable alert in your SIEM. Not four low-priority tickets. One correlated detection. If it does not, your logging provides compliance evidence, not security visibility.
The Hardware Lock Principle: what independent verification means in practice
The core lesson of the Therac-25 is not “test your software more.” AECL tested the software. The race condition was invisible to the test methodology they used because it required a specific timing interaction that did not appear in structured test cases. Running the same test suite more times would not have found it. Testing strategy was not the failure.
The lesson is: when the consequence of failure is catastrophic, the verification mechanism must be structurally independent of the system being verified. Not a second software check running on the same assumptions and logic. A different kind of check.
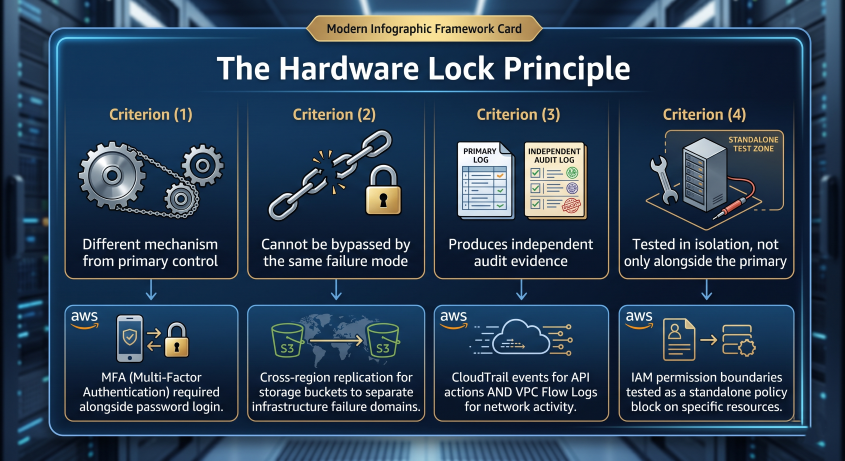
The Hardware Lock Principle applied to cloud security architecture defines independent verification against four criteria:
- Different mechanism from the primary control. A network ACL and a security group both control ingress, but they operate at different OSI layers through different AWS services. An SCP and an IAM policy both restrict permissions, but the SCP applies at the Organisation level through a separate control plane. Different mechanisms mean different failure modes.
- Cannot be bypassed by the same failure mode that defeats the primary control. If a race condition in a Lambda function can corrupt IAM policy state, the independent control cannot itself rely on IAM policy evaluation. If a Terraform misconfiguration can drift a security group, the independent control cannot read from Terraform state to verify it.
- Produces its own independent audit trail. If the logs verifying correct operation are stored in the same account as the control being verified, a failure or compromise in that account can suppress the evidence. Cross-account write-only log destinations with Object Lock enabled are the AWS-native baseline. The audit trail must be outside the blast radius of the control it audits.
- Has been tested in isolation, not only alongside the primary control. A control that has only ever been tested while the primary control was functioning correctly has not been tested. It has been observed not failing under normal conditions. Disable the primary control in a non-production environment and verify the secondary catches the failure independently.
Most cloud security architectures fail criterion 3. CloudTrail logs stored in S3. S3 bucket policies are software controls. A compromised account with IAM write access to the S3 bucket policy can modify log delivery and suppress the evidence of what it did. The audit trail of the attack can be rewritten by the attacker. The Therac-25 wrote its own medical record. So does yours, if your logs live in the same account as your controls.
The action: apply the four Hardware Lock criteria to each of your critical controls. Document which pass, which fail, and what the independent verification gap is. This document is your engineering risk register. It is also the document you do not want to be reading for the first time during an incident review.
The only question that matters
AECL engineers made defensible decisions at every stage. Remove redundant hardware when software handles it. Trust software that has not failed. Attribute individual incidents to operator error before the pattern is visible. Each decision has a reasonable engineering justification. The aggregate of those decisions killed at least three people.
Your CI/CD pipeline, your IaC deployment workflow, your AI-assisted code review, your automated vulnerability scanner: each is making decisions about what is safe to proceed with. Each is doing so based on the state it can observe, through the mechanisms it has access to, using the logic it was configured with. None of them can see their own race conditions.
The question is not whether your automation is good. The question is: what catches it when it is wrong?
If the answer is “the automation itself,” you have built a Therac-25.
The Hardware Lock Principle framework, implementation examples, and control audit template are at blog.ogunlana.net. Apply it to your architecture before you apply it to a post-incident report.
Bola Ogunlana is a Senior DevSecOps Engineer with 25+ years in cloud infrastructure, UK Government delivery, and financial services. He writes at blog.ogunlana.net.